앞에서 EntityManagerFactory와 EntityManager에 대해 배웠다.
emf는 애플리케이션이 실행될 때 최초 한 번만 실행이 되고,
em은 고객 요청마다 생성 되고, 서비스가 끝나면 버린다.
이 때 em을 쓰레드끼리 공유하게 된다면 예상치 못한 "버그"가 생길 수 있기 때문에 필히 close 해야한다.
또한, em은 트랜잭션 단위로 실행된다. 트랜잭션 안에서 실행되지 않으면 JPA가 기능하지 않게 된다.
영속성 컨텍스트(PersistenceContext)
영속성 컨텍스트란 말은 JPA를 배우면서 많이 접하는 용어이다.
"엔티티를 영구 저장하는 환경"이라는 뜻을 가지고 있고,
persist 메서드를 사용하여 객체를 영속화 시킬 수 있다.
영속화한 객체는 EntityManager를 통하여 접근할 수 있다.
엔티티의 생명주기에는
비영속, 영속, 준영속, 삭제 상태가 있다.
비영속 상태는 객체를 생성할 뿐, 영속 컨텍스트에 아직 저장을 안한 상태이다.
persist를 사용하여 객체를 영속 컨텍스트에 저장하게 되면 영속 상태가 된다.
이 때, 영속 컨텍스트에 저장하는 것일 뿐 DB에 저장하는 것이 아니다.
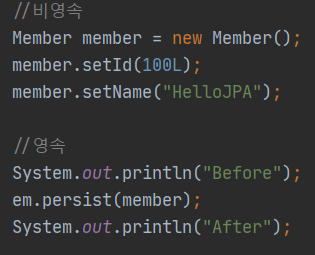

만약 DB에 저장하는 것이라면 Before와 After 사이에 insert 쿼리가 나가야한다.
하지만 console에는 쿼리가 나가지 않음을 알 수 있다.
그렇다면 위에 보이는 쿼리는 언제 나가는 걸까?
트랜잭션이 commit하는 시점에 쿼리가 나가게 된다.
준영속 상태
detach메서드를 사용하여 영속 상태의 엔티티를 영속성 컨테스트에서 분리한다.
즉, 영속성 컨텍스트가 제공하는 기능을 사용하지 못하게 된다.


id가 150L이라는 객체를 조회하여 name을 변경한다.
그러면 JPA가 commit하는 시점에 더티 체킹을 하여 update 쿼리를 날려야한다.
하지만 update 쿼리가 보이지 않는다.
왜?
member를 detach했기 때문에 준영속 상태가 되었다.
그래서 영속성 컨텍스트가 제공하는 기능을 사용하지 못해
update 쿼리가 나가지 않게 된다.
영속 컨텍스트는 왜 사용할까?
영속 컨텍스트는 다양한 이로운 점들이 있다.
1차 캐시, 동일성 보장, 트랜잭션을 지원하는 쓰기 지연, 변경 감지, 지연 로딩 등이 있다.
1차 캐시(조회)
위에서 persist를 이용하여 객체를 영속 컨텍스트에 저장한다고 했다.
1차 캐시란 데이터를 조회할 때, 영속 컨텍스트의 1차 캐시에 데이터가 있다면,
DB에 조회하지 않고 1차 캐시의 값을 가져올 수 있다.


member라는 객체를 persist를 이용하여 영속화 시켰다.
그리고 find라는 메서드로 101L id를 가진 객체를 조회했다.
이 때, DB를 조회하는 select가 나가지 않음을 알 수 있다.
객체의 정보가 영속 컨텍스트의 1차 캐시에 저장되어 있기 때문에 DB에 조회하지 않는다.


1번에서는 select 쿼리가 나간다.
왜?
데이터를 조회할 때, 1차 캐시에 없으니 DB에서 직접 조회해야한다.
2번에서는 select 쿼리가 나가지 않게 된다
왜?
1번 과정을 통해 id가 101L 인 객체를 조회했다. 그러면서 1차 캐시에 저장이 된다.
똑같이 id가 101L인 객체를 조회할 때에는 1차 캐시에 저장되어 있기 때문에
DB에 조회하지 않으면서 select 쿼리가 나가지 않게 된다.
쓰기 지연(등록)
엔티티를 DB에 등록하기 위해서는 insert쿼리가 나가야하고, 값을 변경하기 위해선 update 쿼리가 나가야한다.
JPA에서는 "쓰기 지연" 이라는 기능으로 매번 엔티티를 저장할 때마다 DB에 쿼리를 날리지 않고,
쓰기 지연 SQL 저장소라는 곳에 필요한 쿼리들을 모두 저장한 뒤에 한 번에 쿼리를 날린다.
쓰기 지연은 DB에 보낼 쿼리들을 매번 보내지 않고,
한번에 모아놨다가 commit 하는 시점에 쿼리들이 나가게 된다.


member1과 member2를 영속화시킬 때, db에 insert를 시키는 쿼리가 있을 것이다.
하지만 1번과 2번을 보면 쿼리가 나가지 않음을 알 수 있다.
이는 JPA가 entity를 분석해서 insert sql를 생성하여 "쓰기 지연 SQL 저장소"에 저장한 것이다.
즉, 1,2번에서 생성된 쿼리들은 현재 "쓰기 지연 SQL 저장소"에 저장됐다.
그래서 트랜잭션이 commit되는 3번 시점에서 쿼리들이 나가게 된다.
트랜잭션을 지원하는 쓰기 지연이 가능한 이유가 뭘까?
데이터를 저장하는 즉시 쿼리를 날리든, 한번에 모아둔 뒤 커밋 시점에 쿼리를 날리든지 간에
결국 트랜잭션을 커밋하지 않으면 아무 소용이 없기 때문에
결국 커밋 전에만 DB에 SQL을 전달하면 된다.
변경 감지(수정)


id가 150L인 객체를 조회하여 name을 바꾸게 되면
따로 persist를 하지 않아도 update 쿼리가 나가는 것을 볼 수 있다.
왜 persist를 사용하지 않아도 될까?
JPA의 목적은 자바 컬렉션을 다루듯 객체를 다루는 것이다.
우리가 컬렉션에서 값을 꺼내어 변경하게 되면 다시 값을 집어넣을까?
그렇지 않다. 그래서 persist를 사용하지 않는다.
그렇다면 어떻게 작동되는 걸까?
JPA는 1차 캐시에 값이 들어올 그 최초 시점의 상태를 스냅샷으로 저장해놓는다.
그리고 commit하는 시점에 내부적으로 flush를 실행하면서 entity와 스냅샷을 비교한다.
member를 조회할 때, 영속화되는 시점의 스냅샷을 저장한다.
변경하고 commit하는 시점에 JPA가 저장해뒀던 스냅샷과 entity를 비교한다.
그래서 member가 바뀌게 되면 update 쿼리를 쓰기 지연 SQL에 저장을 해놓은 뒤,
flush가 일어나면 DB에 쓰기 지연 SQL에 저장되있던 쿼리들을 날리게 된다.
하지만 사진에서는 나오지 않았지만, 필드에 여러 개 있다면 JPA는 기본 전략으로 모든 필드를 업데이트 한다.
@org.hibernate.annotations.DynamicUpdate어노테이션을 사용하면 수정된 데이터만 사용해서 동적으로 UPDATE SQL을 생성한다.
플러시
flush를 하게 되면 쓰기 지연에 저장되있던 SQL들을 실제 DB에 날려주게 된다.
조심해야할 점이 flush를 한다해도 1차 캐시가 지워지는 것이 아니다.
오직 영속 컨텍스트에 있는 쓰기 지연 SQL 저장소에 있는 것들(변경 감지 포함)이
DB에 반영되는 과정이다.
플러시는 트랜잭션 작업 단위가 있기 때문에 가능하고,
커밋 직전에만 flush를 실행하여 동기화하는 것이 중요하다.


member 객체를 저장하기 위해 insert 쿼리가 persist 시점에서 쓰기 지연 SQL에 저장된다.
그래서 flush가 실행되어 쓰기 지연 SQL에 저장되있던 쿼리가 실제 DB로 간다.
commit 다음에는 쓰기 지연 SQL에 저장되있는 SQL이 없기 때문에
실행할 쿼리가 없어서 console에 뜨지 않는다.
준영속 상태 수정
준영속 상태 엔티티를 수정하는 방법은 변경 감지 기능, 병합 사용이 있다.
변경 감지
준영속 상태는 비영속 상태, 영속 상태의 특징을 각각 가지고 있다.
영속성 컨텍스트가 관리하지 않는 상태인 비영속 +
DB에 저장이 한번 저장되어 "식별자"가 존재하는 영속 ( 식별자 직접 할당하지 않음 )
이 두 가지 특징을 가지고 있다.
그래서 준영속 상태에서는 값을 수정할 때, 영속성 컨텍스트가 관리하지 않기 때문에
영속성 컨텍스트의 특징(변경 감지, 쓰기 지연 등)을 사용할 수 없다.
즉, 준영속 상태의 엔티티를 가지고 값을 수정해도 제대로 수정되지 않는다.
그렇다면 어떻게 해야할까?
바로 준영속 상태의 식별자를 이용하여 repository에서 엔티티를 조회하여 1차 캐시에 올려놓는다.
즉, 가져온 엔티티는 영속 상태임을 나타낸다.
해당 엔티티를 이용하여 값을 변경하면 변경 감지가 된다.
병합
public void update(Item changeItem) {
Item mergeItem = em.merge(changeItem);
}merge를 사용하게 되면 준영속 상태의 식별자를 통해 DB에서 영속 상태의 엔티티를 조회하게 된다.
그리고 changeItem을 영속 상태의 엔티티에 덮어 씌운다. 그리고 영속 상태의 엔티티를 반환하게 된다.
즉, changeItem은 준영속 상태를 유지하고, mergeItem은 영속 상태이다.
changeItem이 준영속 -> 영속 으로 바뀌는 것이 아니라 영속 상태의 엔티티에 changeItem의 값을 덮어 씌우는 것임을 꼭 기억하자.
여기서 덮어 씌운다라는 말로 인해 merge 사용을 지양해야 한다.
예를 들어 현재 item의 가격은 1000원이다. 하지만 changeItem에서는 item의 가격이 null로 되어있다.
그렇다면 반환된 엔티티의 item가격은 null이 되므로 매우 위험하다.

병합은 엄밀히 말하면 준영속, 비영속을 구분하지 않는다.
엔티티의 식별자 값으로 영속성 컨텍스트 조회, 없으면 DB를 조회한다.
만약 발견이 되었다면 entity를 1차 컨텍스트로 가져온다.
-> 이 경우는 준영속 엔티티
만약 비영속 엔티티라면 식별자 값이 존재하지 않을 것이다.
이 때 merge를 사용한다면 새로 생성해서 병합을 하게 된다.
즉, DB에 해당 엔티티의 식별자가 존재한다면 병합을 하고,
없다면 엔티티를 새로 생성하여 저장한다.
Reference
자바 ORM 표준 JPA 프로그래밍 (김영한)
'Spring 강의 > JPA - 기본편' 카테고리의 다른 글
| 고급 매핑 (0) | 2021.12.07 |
|---|---|
| 다양한 연관관계 매핑 (0) | 2021.12.02 |
| 연관관계 매핑 기초 (0) | 2021.11.29 |
| 앤티티 매핑 (0) | 2021.11.20 |
| JPA 시작하기 (0) | 2021.11.17 |
