영한님 스프링 강의를 들으면서 스트림을 사용하시는 것을 보고,
실무에서도 스트림을 많이 사용하는구나 라는 생각이 들었다
이번 기회에 스트림을 제대로 공부해보고자,
옛날에 들었던 "윤성우의 열혈 Java"를 통해 스트림을 공부하게 됐다.
뭔가 필요한 공부를 하니 강의를 들으면서 더욱 집중할 수 있었고,
빨리 내 프로젝트에 적용해보고 싶은 욕구가 생겼다.
스트림
일련의 과정을 부드럽게 해결하기 위해 사용한다.
물이 흐르면서 필터를 거쳐 우리가 마실 수 있는 물이 되는 것처럼,
데이터가 흐르면서 여러 필터를 거치며 우리가 원하는 데이터를 얻을 수 있다.
스트림은 중간 연산과 최종 연산으로 나뉜다.
중간 연산은 마지막이 아닌 위치에서 진행되는 연산으로, 각각 순서가 바뀔 수 있다.
최종연 산은 마지막에 진행되는 연산으로 무조건 마지막에 위치해야 한다.
int[] ar = {1, 2, 3, 4, 5};
IntStream stm1 = Arrays.stream(ar);
IntStream stm2 = stm1.filter(n -> n % 2 == 0);
int sum = stm2.sum();
System.out.println(sum);
int sum1 = Arrays.stream(ar)
.filter(n -> n % 2 == 1)
.sum();
System.out.println(sum1);
배열에서 짝수들의 합을 구하는 코드이다.
스트림을 사용하지 않게 되면 for문을 통해 짝수를 찾고, 그때마다 더해줄 것이다.
하지만 스트림을 사용하게 되면 위와 같이 간결하게 코드를 작성할 수 있다.
-> 이 점이 너무 매력적으로 다가왔다.. 코드가 너무 간결해진다.
stream 메서드를 통해 스트림을 stm1에 저장한다.
filter 메서드를 통해 걸러진 스트림을 stm2에 저장한다.
마지막으로 sum 메서드를 통해 최종 연산을 하게 된다.
이때 신기한 점이 있다.
스트림의 연산은 지연(Lazy) 방식으로 동작한다고 한다.
어? spring boot에서 lazy 방식을 사용해야 한다고 했다. 그와 똑같은 개념이다.
메서드 호출이 filter에서 sum으로 이어진다.
하지만 sum이 호출될 때까지 filter의 호출 결과는 스트림에 반영되지 않는다.
즉 최종 연산인 sum이 호출되어야 filter의 호출 결과가 스트림에 반영되고,
sum의 호출 결과가 스트림에 반영된다고 한다.
스트림 생성
스트림 생성 종류에는 인자 직접 전달, 배열, 컬렉션이 있다.
인자 직접 전달


인자로 직접 전달하여 스트림을 생성할 수 있다. 또한, 가변 인자로도 전달하여 생성할 수 있다.
배열
배열은 위에서 보다시피 스트림을 생성할 수 있다.

Arrays.stream(array)위와 동일하게 스트림을 생성하는 메서드이지만, 배열의 start, end index를 파라미터로 사이의 값만 스트림에 저장할 수 있다.

arr = [1,2,3,4,5]
Arrays.stream(arr, 1, 4)
.forEach(s -> System.out.print(s + " "));
// 출력 값: 2 3 4
컬렉션
컬렉션은 레퍼런스를 보면 아래와 같은 메서드가 정의되어 있다.

list.stream()을 사용하면 스트림을 생성할 수 있다.
중간 연산(필터링, 맵핑, 정렬, 루핑)
필터링
데이터를 조건에 따라 걸러내는 기능이다.

Predicate

filter 메서드의 매개변수 형은 Predicate로 test 메서드를 통해 조건에 따라 true, false를 반환한다.
ArrayList<Integer> al = new ArrayList<>();
for (int i = 1; i <= 5; i++) al.add(i);
al.stream()
.filter(s -> s > 3)
.forEach(e -> System.out.println(e));
// 출력 값 : 4 5
맵핑
맵핑은 쉽게 생각하면 문자열을 문자열의 길이로 나타낼 수 있다
즉, 스트림의 데이터 형이 달라지게 된다.

map의 매개변수 형은 Function이다.
Function은 "들어왔다 나간다"라고 생각한다.
T는 들어오는 인자, R은 반환된 인자이다.
ArrayList<String> al = new ArrayList<>();
al.add("A");
al.add("AB");
al.add("ABC");
al.add("ABCD");
al.stream()
.map(s -> s.length())
.forEach(e -> System.out.println(e));
//출력 값 : 1 2 3 4
T는 String, R은 Integer다.
왜?
제네릭이기 때문에 int가 올 수 없다.
따라서 자동적으로 오토 박싱과 언박싱이 이뤄진다.
박싱과 언박싱이 이뤄지지 않게 하려면 map의 친구들인
map 대신 mapToInt, mapToLong, mapToDouble을 사용하면 된다.
flatMap

map과 파라미터를 비교해보면 flatMap에 전달할 람다식에서는 스트림을 생성하고 이를 반환해야한다.
즉, 쉽게 말하면 하나의 스트림에 대하여 여러 값이 나올 때 사용할 수 있다. ( 1 : * )
아래의 예를 보면 String을 char로 나타내기 위한 코드이다.
Hello -> H e l l o
하나의 String 에 5개의 char가 반환된다.
따라서 flatMapToInt를 사용하여 IntStream을 반환하고,
mapToObj 메서드로 Stream<Character>을 반환한다!
List<String> li = new ArrayList<>();
li.add("Hello");
li.add("World");
li.stream()
.flatMapToInt(s-> s.chars())
.mapToObj(ch -> (char)ch)
.forEach(c -> System.out.print(c + " "));
//출력값 : H e l l o W o r l d
정렬

파라미터로 Comparator에 대한 람다식을 받는다.
정렬의 기준을 정하여 sorted의 파라미터로 넘기면 된다.
당연히 기준을 명시하지 않으면 오름차순 정렬이 된다.
List<String> li = new ArrayList<>();
li.add("B");
li.add("C");
li.add("A");
li.add("D");
li.stream()
.sorted()
.forEach(s -> System.out.print(s + " "));
System.out.println();
//역순
li.stream()
.sorted((o1, o2) -> {return o2.compareTo(o1);})
.forEach(s -> System.out.print(s + " "));
// 출력 값 : A B C D
// 출력 값 : D C B A
루핑(Looping)
Loop은 반복문 즉, 스트림을 이루는 모든 데이터를 각각 특정 연산을 진행하게 된다.
어? 그렇다면 forEach가 있는데 굳이 이걸 사용할 필요가 있을까?
forEach는 최종연산, peek는 중간 연산이다. 스트림을 생성하다보면 중간 연산에 각각 데이터를 접근하는 일이 생길 수 있기 때문에 알아놓는 것이 좋다.

List<Integer> li = new ArrayList<>();
li.add(1);
li.add(3);
li.add(4);
li.add(5);
//최종 연산 X
li.stream()
.peek(s -> System.out.println(s + " "));
System.out.println();
//최종 연산 O
int sum = li.stream()
.peek(s -> System.out.print(s + " "))
.mapToInt(s -> s)
.sum();
//출력 값 : 1 3 4 5원래 예상한 출력은
1 3 4 5
1 3 4 5인데 1 3 4 5만 나왔다.
왜 그럴까?
앞에서 우리는 스트림이 Lazy 처리를 한다고 했다.
최종 연산이 없는 스트림은 중간 연산이 진행되지 않게 된다.
만약 Lazy가 아니라 즉시 처리였다면 예상한 출력대로 나왔을 것이다.
최종연산(리덕션, 계산메서드)
리덕션
reduce는 최종 연산을 대표하는 메서드이다.
리덕션이란 데이터를 축소하는 연산을 뜻한다
즉, 우리가 앞선 sum도 리덕션 연산이다.
1+2 = 3 + 3 = 6 + 4 = 10 + 5 = 15 요런 식으로 데이터를 축소하며 연산이 진행된다.
이처럼 sum은 이미 연산의 내용이 정해져 있다.
하지만 아래의 reduce 메서드는 우리가 전달하는 람다식에 의해 연산의 내용이 결정된다.

BinaryOperator<T>

T identity는 기준(?)이라고 생각하면 될 것 같다.
예를 들어 스트림에 현재 아무것도 없을 경우, identity를 반환한다.
또한, 문자열의 길이가 가장 긴 것을 출력할 때, identity가 가장 길다면,
identity를 반환하게 된다.
즉 identity는 스트림에서 제일 앞쪽에 위치한다고 생각하면 된다.
ArrayList<String> al = new ArrayList<>();
al.add("A");
al.add("AB");
al.add("ABC");
al.add("ABCD");
BinaryOperator<String> bo = (o1, o2)->{
if(o1.compareTo(o2) < 0)
return o2;
return o1;
};
String str = al.stream()
.reduce("", bo);
System.out.println(str);
String str1 = al.stream()
.reduce("BBBBB", bo);
System.out.println("str1 = " + str1);str은 ABCD
str1은 BBBBB가 나오게 된다.
계산 메서드
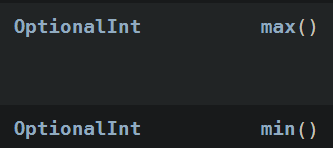
sum, count, average, min, max 메서드가 있다.
average, min, max는 Optional이 감싸져서 반환되기 때문에
따로 처리를 해줘야한다!
그 외 allMatch, anyMatch, noneMatch도 있다.
Reference
윤성우의 열혈 자바 (윤성우 지음)
https://docs.oracle.com/en/java/javase/11/docs/api
'Java' 카테고리의 다른 글
| Java volatile keyword (0) | 2022.04.18 |
|---|---|
| final 키워드 (0) | 2022.03.05 |
| ==와 equals의 차이 (0) | 2021.05.25 |
| String Operator '+' 의 작동 원리(2022.03.24 수정) Java 9 (0) | 2021.05.25 |
| Object 메소드 (0) | 2021.05.24 |
